

Technical
The Language Processing Framework
-
Technical documentation: Language processing chains



One of the most recent developments in NLP is the emergence of linguistic annotation meta-systems which make use of existing processing tools and implement pipelined architecture. This chapter describes a system that offers a new perspective in exploiting NLP meta-systems by providing a common processing framework. This framework supports most of common NLP tasks by chaining tools that are able to communicate on the basis of common formats.
Several standardization approaches have been made towards the interoperability of the NLP tools (XCES, TEI, GOLD). None of the proposed standards have been universally accepted, leading to the development of resources and tools according to the format of each research project. More notably, two systems that facilitate the access and usage of existing processing tools have emerged. GATE (Cunningham et al., 2002) is an environment for building and deploying NLP software and resources that allows integration of a large amount of built-ins in new processing pipelines. UIMA (Unstructured Information Management Application) (Ferrucci and Lally, 2004) offers the same general functionalities as GATE but once a processing module is integrated in UIMA it can be used in any further chains without any modifications (GATE requires wrappers to be written to allow two or more modules to be connected in a chain). Currently, UIMA is the only industry OASIS standard (Ferrucci et al., 2006) for content analytics.
Requirements
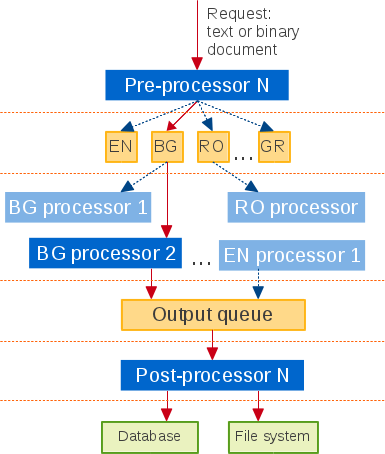
The key requirements to our system are the possibility to use heterogeneous NLP tools for different languages, transparent horizontal scalability, and transparent hot-swap of linguistic components. Last but not least is the requirement of a minimal installation footprint.
Architecture
After evaluating both GATE and UIMA meta-systems, in respect to the above requirements, we based the implementation of the processing engine on the UIMA framework (JAVA version). We wrapped the UIMA base framework with an OSGi shell (OSGi Alliance, 2009), making it available to the rest of the components in the system. The horizontal scalability of the NLP functionalities and the transparent hot-swap of the linguistic components are empowered by a network-distributed architecture based on ActiveMQ.
Pre-processing phase
The main task performed by the pre-processing phase of the linguistic framework in ATLAS is to extract the textual content from various document sources and send it to the corresponding language processing chain (LPC). This process consists of a mime detector, text extractor and language detector. The architecture of the pre-processing platform is based on the OSGi implementation from Eclipse – Equinox and allows flexible, plugin- and feature-oriented deployment. In other words, one component, or subcomponent, can be easily replaced with an alternative implementation which provides the same functionality.
MIME type detector
The mime type detector is responsible for detecting the correct mime type of an unknown document sources. The implementation of this sub-component is based on two external tools, available only for Linux platforms:
- “/usr/bin/file” – when invoked with „-i” or „--mime” and a filename the tool returns the detected mime type of the file and its character encoding;
- „gnomevfs-info” – this tool provides a lot more information about the file, including its mime type.
The precision of the „gnomevfs-info” tool is higher than the the „/usr/bin/file” and is preffered mime type detection program if gnome shell is available. Below is an example, how the mime type is extratced from the fill information of a file:
gnomevfs-info -s /tmp/video | awk '{FS=":"} /MIME type/ {gsub(/^[ \t]+|[ \t]+$/, "",$2); print $2}'
Text extractor
Once the mime type of the document source is detected, pre-processing engine is able to extract the text from the source, using mime-specific text extractor. The list below shows the currently available text extractors in ATLAS.
application/x-fictionbook+xml
application/x-chm
application/x-mobipocket-ebook
application/prs.plucker
image/vnd.djvu
application/epub+zip
text/html
application/xhtml+xml
application/x-ms-reader
application/x-obak
application/x-mimearchive
message/rfc822
application/vnd.ms-office
application/msword
application/vnd.ms-powerpoint
application/vnd.ms-excel
application/vnd.openxmlformats-officedocument.wordprocessingml.document
application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
application/vnd.openxmlformats-officedocument.presentationml.presentation
application/vnd.oasis.opendocument.text
application/pdf
text/rtf
application/rtf
A fallback text extractor is used if none of the available text extractors manage to return the textual content of the document. The external executable is using OpenOffice headless installation to convert documents from various formats to plain test. This exctrator requires significantly more resources (CPU and Heap), thus it is used as a last-resort to retrieve the text from a document.
Language recognizer
The language detection sub-component is based on NGramJ java library (htt p://ngramj.sourceforge.net/). The n-gram language profiles have been extended with a model for the Croatian language, built on a corpus of Croatian Wikipedia articles.
Language processing chain
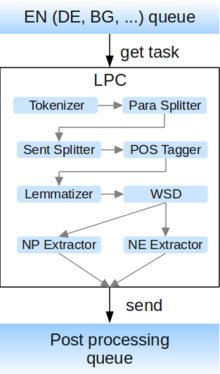
At this stage the text is annotated by several NLP tools, chained in a sequence. We call the implementation of the processing engine for a specific language a ‘Language Processing Chain’ (LPC).
In order to achieve a basic set of low-level text annotations the following atomic NLP tools have to be executed in sequence (Cristea and Pistol, 2008): Paragraph splitter (splits the raw text in paragraphs) → Sentence splitter (splits the paragraphs in sentences) → Tokenizer (splits the sentences into tokens) → POS tagger (marks up each token with its particular part of speech tag) → Lemmatizer (determines the lemma for each token) → Word sense disambiguation (disambiguates each token and assigns a sense to it) → NounPhrase Extractor (marks up the noun phrase in the text) → NamedEntity Extractor (marks up named entities in the text). “Figure 1” overviews the contents and the sequence of execution of the atomic NLP tools, part of a LPC.
UIMA implementation of a LPC
A typical UIMA application consists of: a Type System Descriptor, describing the annotations that will be provided by the components of the application; one or more Primitive Analysis Engines, each one providing a wrapper for a NLP tools and adding annotations to the text; an Aggregate Engine, defining the execution sequence of the primitive engines (Gordon et al., 2011).
Type System Descriptor
In order to put the atomic NLP tools in a chain, they need to be interoperable on various levels. The first interoperable level, the compatibility of formats of linguistic information, is supported by a defined scope of required annotations, described as a UIMA Type System Descriptor. The uniform representation model, required by the UIMA type system, provides normalized heterogeneous annotations of the component NLP tools. Within our system, it covers properties that are critical for the further processing of annotated data, e.g. lemma, values for attributes such as gender, number and case for tokens necessary to run coreference module to be subsequently used for text summarization, categorization and machine translation. To facilitate introduction of further levels of annotation, a general markable type has been introduced, carrying subtype and reference to another markable object. In this way we can test and later include new annotation concepts into the core annotation model.
Post-processing phase
At this stage the annotations are stored in a data store, such as file system, relational or NoSQL database or a combination of these data stores. The current version of ATLAS uses a fusion data source based on PostgreSQL relation database and fast Lucene indexes.
Relational storage
Each document is represented as a sequence of tokens, noun phrases (NPs) and named entities (NEs). In order to compare two document the components of the token, NPs and NEs form a numeric feature space. The follwoing rules are applied when two annotations are compared:
- tokens - two tokens are assumed equal if their lemmas, POS tags and word senses are the same;
- noun phrases - two noun phrases are assumed equal if they consists of one and the same list of tokens. The "noise" words are removed prior comparing two NPs. For examaple the phrases "the blue sky" and "a blue sky" are equal, because the determiners "a" and "the" are ommited.
- named enitites - being noun phrases, two named enitites are considered equal if they both consists of one and the same list of tokens.
An annotation is firstly saved in a relational database if it is found not found in the database. Further on, the annotation is represented by its identificator (id) in the content of the document. In this way, document is presented with several vecotrs in N-dimentional feature space and we can apply different statistical algoritms, such as feature redutrction, automatic categortization, cosine ditance between documents, etc...
Lucene index
As mentioned above, each document is presented with sevral n-dimentional vectors. Such representation is convenient for further processing of the document but is not very easy to be stored and manuipulated in a relational database. One of the problems related to this representation is the amount of data that should be stored are database rows. Thus, we adoped another approach and the document vectors are stored in a Lucene index. Each document vector consists of numeric values so a simple "WhitespaceAnnalyzer" (org.apache.lucene.analysis.WhitespaceAnalyzer) is used for storing and searching in the indexes. The performance for storing and retreiving document information is constant in the scope of 1'000'000 documents with an average 23'000 tokens per document.
The utilization of Lucene as datasotrce allows is to execute queries with optimal performance, such as:
- finding similar document to a selected on - in this case we use a modified version of the "MoreLikeThis" (org.apache.lucene.search.similar.MoreLikeThisQuery) Lucene query;
- finidng documents containing one or more common noun phrases or named entities;
- finding the most important concepts (noun phrases) for a given document.
Extending the post-processing phase
ATLAS, being based on OSGi technology, provides an extensible post-processing framework. In other words, one can implement its own storage strategy by implementing a service based on the "com.tetracom.atlas.tm.postprocessing.api.IStore" interface. The raw CAS, as well as the domain, document identifier, document languages and performance report are available in the "com.tetracom.atlas.tm.postprocessing.api.IStoreTask" parameter. For example, the input for the PoS-factotred machine tranlsation models has been created by a custom implemnetation of IStore service.
; return false;") |
; return false;") |
ATLAS (Applied Technology for Language-Aided CMS) is a project funded by the European Commission under the CIP ICT Policy Support Programme.